Extract text from images using Amazon Textract
No one can deny the digitalization of our world: most use smartphones for daily communications, reading news, and taking photos and notes. Many people thought we would go 100% digital, but we still use pen and paper instead. I was one of them when I saw one of the first Palm PDAs. But the expectations have yet to become real, and I still use my pen and notebook to take notes.
Handwritten notes are excellent when taking them during a meeting or lecture, but they are not searchable, hard to edit, etc. That's why I always try to convert the important ones to a digital form by scanning to PDF and converting them into text using Amazon Textract service.
Amazon Textract is a machine learning service in that Amazon Web Services (AWS) automatically extracts text and data from scanned documents, PDFs, and images. It uses advanced optical character recognition (OCR) technology and machine learning algorithms to identify and extract text, tables, forms, and other document data.
Amazon Textract can work with various file formats, including PDF, PNG, and JPG, and it can extract data from structured and unstructured documents. The service also includes table and form identification features, which can help automate data entry and reduce errors.
Amazon Textract has two processing modes: synchronous and asynchronous. In synchronous mode, Textract processes the document and returns the results immediately. The application requesting the document analysis will wait for Textract to complete the processing and return the results before continuing. The main limitation of this mode is you can parse only one page per request. It does not work for me since I usually scan all pages to one PDF document and convert it to text.
In asynchronous mode, Textract processes the document in the background and returns the results later, either by writing the results to an S3 bucket or by sending a notification to an Amazon Simple Notification Service (SNS) topic.
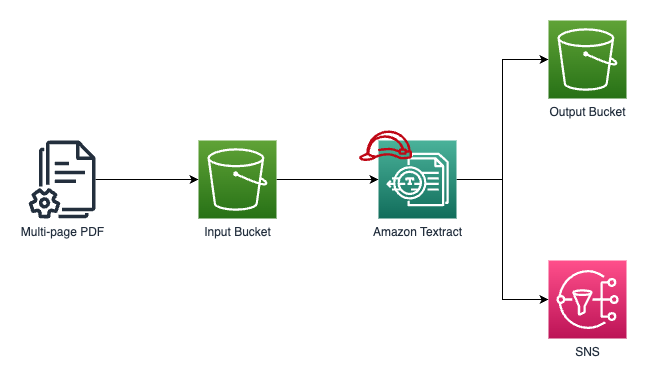
Usually, I use Python for my automated scripts. The sample code also utilizes Boto3 library (AWS SDK for Python). Make sure you installed it.
pip install boto3
First, you need to create your input and output S3 buckets. Make sure that your user or role has permission to access them. At a minimum, you will need the following policies attached to your IAM user or role:
- AmazonTextractFullAccess
- AmazonS3ReadOnlyAccess
- AmazonSNSFullAccess
- AmazonSQSFullAccess
Of course, if you use the same user to upload the PDF, it must have write access to S3 (s3:PutObject action).
Second, you need to create a service role for Amazon Textract to be able to send SNS notifications.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "",
"Effect": "Allow",
"Principal": {
"Service": "textract.amazonaws.com"
},
"Action": "sts:AssumeRole",
"Condition": {
"ArnLike": {
"aws:SourceArn": "arn:aws:textract:*:000000000000:*"
},
"StringEquals": {
"aws:SourceAccount": "000000000000"
}
}
}
]
}
You will need to replace 000000000000 with your AWS Account ID.
It is unusual to see the Conditions sections in service roles, but it is a recommended practice for Cross-service confused deputy prevention
Cross-service confused deputy prevention is a security feature in Amazon Web Services (AWS) that helps prevent a "confused deputy" attack. In this attack, a trusted service or resource is tricked into acting on behalf of an attacker, who can exploit a vulnerability in the trusted service or resource to gain unauthorized access.
Third, you should grant iam:PassRole permission to your IAM user or role that you will use to start the image recognition job. For example, you can create it as an inline policy associated with the IAM User.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "iam:PassRole",
"Resource": "arn:aws:iam::000000000000:role/TextractSampleRole"
}
]
}
Finally, create and subscribe to the Amazon SNS topic to ensure you get job completion notifications. When you create the Amazon SNS topic, you must use the prefix AmazonTextract, for example, AmazonTextractSampleCompletionNotifications.
We are ready to run the job using Python. Please make sure you use your parameter in the script.
import boto3
from pprint import pprint
FILENAME = "sample.pdf"
S3_BUCKET = "textract-sample-000000000000"
INPUT_PREFIX = f"input/{FILENAME}"
ROLE_ARN = "arn:aws:iam::000000000000:role/TextractSampleRole"
SNS_TOPIC = "arn:aws:sns:us-east-1:000000000000:AmazonTextractSampleCompletionNotifications"
def main():
# Upload sample PDF file to S3
s3 = boto3.client("s3")
s3.upload_file(FILENAME, S3_BUCKET, INPUT_PREFIX)
print(f"Uploaded sample.pdf to s3://{S3_BUCKET}/{INPUT_PREFIX}")
# Use Amazon Textract to detect text in the sample PDF file
textract = boto3.client("textract")
response = textract.start_document_text_detection(
DocumentLocation={"S3Object": {
"Bucket": S3_BUCKET, "Name": INPUT_PREFIX}},
OutputConfig={"S3Bucket": S3_BUCKET, "S3Prefix": "output"},
NotificationChannel={"RoleArn": ROLE_ARN, "SNSTopicArn": SNS_TOPIC},
)
pprint(response)
print("DONE.")
if __name__ == "__main__":
main()
All source code from the sample is available on GitHub
If everything is OK, the app will return the Job ID you may use to get the extracted text.
$ python3 ./recognize.py
Uploaded sample.pdf to s3://textract-sample-234234234/input/sample.pdf
{'JobId': '5e3147084930cc653ec657b7a653e619566e2ef3d76cc7bf4ea8382a8c0f4c5d',
'ResponseMetadata': {'HTTPHeaders': {'content-length': '76',
'content-type': 'application/x-amz-json-1.1',
'date': 'Sun, 22 Jan 2023 07:10:48 GMT',
'x-amzn-requestid': '81312252-d875-4797-924f-1606798c8cea'},
'HTTPStatusCode': 200,
'RequestId': '81312252-d875-4797-924f-1606798c8cea',
'RetryAttempts': 0}}
DONE.
Once you get a notification through SNS, you can run another Python script to create a text document from the Textract's output.
import time
from pprint import pprint
import boto3
JOB_ID = "5e3147084930cc653ec657b7a653e619566e2ef3d76cc7bf4ea8382a8c0f4c5d"
def main():
textract = boto3.client("textract")
next_token = None
while True:
# You cannot pass NextToken = "" or NextToken = None to the API since it will throw errors:
# "Invalid type for parameter NextToken, value: None, type: <class 'NoneType'>, valid types: <class 'str'>"
# "Invalid length for parameter NextToken, value: 0, valid min length: 1"
if next_token is None:
response = textract.get_document_text_detection(JobId=JOB_ID)
else:
response = textract.get_document_text_detection(
JobId=JOB_ID, NextToken=next_token)
if response["JobStatus"] == "SUCCEEDED":
# Extract text from the response
for block in response["Blocks"]:
if block["BlockType"] == "LINE":
print(block["Text"])
# Check if there are more pages to process
if "NextToken" in response:
next_token = response["NextToken"]
else:
break
elif response["JobStatus"] == "FAILED":
raise Exception(f"Job {JOB_ID} failed.")
else:
print("Waiting for job to complete...")
time.sleep(5)
print("DONE.")
if __name__ == "__main__":
main()
Make sure you passed the correct Job ID to the script. The Job ID will be available only for 7 days!
My use case is simple, but if you require more advanced operations with the response, you may check some open source libraries provided by AWS. Otherwise, consider reading Amazon Textract Response Objects specification.
Summary
We discussed the benefits of using Amazon Textract to convert handwritten notes into digital form. Textract is an Amazon Web Services (AWS) machine learning service that automatically extracts text and data from scanned documents, PDFs, and images. It uses advanced optical character recognition (OCR) technology and machine learning algorithms to identify and extract text, tables, forms, and other document data. In the article, I explained the two processing modes available in Textract, synchronous and asynchronous, and provided a sample code for setting up a Textract job. The article also highlights the security features available in AWS, including cross-service confused deputy prevention, to prevent attacks on trusted services or resources.